Solr core configuration
Docs and sources:
- solrconfig.xml
- managed-schema.xml
- Field Types Included with Solr
- docValues
- Understanding SOLR Field Properties: Indexed, Stored and docValues
- DocValues VS Stored Fields: Apache Solr Features and Performance SmackDown
- Document Analysis
- External files
File structure of a core/conf directory
rafal@MacBook-Pro-Rafal solr-9.7.0 % ls -l server/solr/mycore/conf
total 108
drwxr-xr-x 41 rafal staff 1312 Sep 4 00:06 lang
-rw-r--r-- 1 rafal staff 50695 Sep 4 00:06 managed-schema.xml
-rw-r--r-- 1 rafal staff 873 Sep 4 00:06 protwords.txt
-rw-r--r-- 1 rafal staff 44800 Sep 4 00:06 solrconfig.xml
-rw-r--r-- 1 rafal staff 781 Sep 4 00:06 stopwords.txt
-rw-r--r-- 1 rafal staff 1124 Sep 4 00:06 synonyms.txt
Most important files:
managed-schema.xml- schema of the data. Previously known asschema.xmlsolrconfig.xml- configuration of the core, for example:- defining handlers (
/selectfor searching,/updatefor indexing), query parsers, etc - adding plugins
- merge policy
- replication
- see docs
- defining handlers (
managed-schema.xml
<?xml version="1.0" encoding="UTF-8" ?>
<schema name="default-config" version="1.7">
<!-- field types -->
<fieldType name="string" class="solr.StrField" docValues="true"/>
<!-- fields -->
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false"/>
<dynamicField name="*_s" type="string"/>
<!-- unique key -->
<uniqueKey>id</uniqueKey>
<!-- copy fields -->
<copyField source="sourceFieldName" dest="destinationFieldName"/>
</schema>
A good documentation is in the comments in the default managed-schema.xml file in the Solr
distribution: managed-schema.xml
Noteworthy: field types
<fieldType
name="id"
class="solr.StrField"
sortMissingLast="true"
sortMissingFirst="false"
multiValued="false"
indexed="true"
stored="true"
docValues="true"
/>
All field types: Field Types Included with Solr
Some common types:
solr.StrField- text saved "as is", not analyzed, not tokenizedsolr.TextField- text after tokenization and analysissolr.BoolFieldsolr.DoublePointFieldsolr.IntPointFieldsolr.DatePointFieldsolr.ExternalFileField- value of this field os stored in a separate file, mainly for function queries
Three important data structures: indexed/stored/docValues
Let's say we have the following documents:
<add>
<doc>
<field name="id">Car 1</field>
<field name="name">VW Golf hatchback</field>
<field name="price">200</field>
</doc>
<doc>
<field name="id">Car 2</field>
<field name="name">Toyota Corolla hatchback</field>
<field name="price">100</field>
</doc>
<doc>
<field name="id">Car 3</field>
<field name="name">Toyota Auris Touring</field>
<field name="price">50</field>
</doc>
</add>
Inverted index: indexed="true"
Per-field data structure, pointing from tokens (words) to docIds
Index for field "name":
"vw" => Car 1
"golf" => Car 1
"hatchback" => Car 1, Car 2
"toyota" => Car 2, Car 3
"corolla" => Car 2
"auris" => Car 3
"touring" => Car 3
Index for field "price":
50 => Car 3
100 => Car 2
200 => Car 1
Used for quick searching for documents with given tokens
Example
- Query: "Toyota Hatchback"
- Index lookup:
- Intersection of those sets:
{Car 2, Car 3} ∩ {Car 1, Car 2} = {Car 2} - Final result set:
{Car 2}
Use cases: full-text search or filtering
Column-based token storage: docValues="true"
Per-field data structure, pointing from docIds to field values. See docValues docs
Note: docValues can be enabled only for some field typed. TextField is not among them.
DocValues for field "name":
<can't be created>
DocValues for field "price":
Car 1 => 200
Car 2 => 100
Car 3 => 50
Used for retrieving valued during operations like sorting or faceting
Use cases:
- sorting
- faceting
- grouping
- function queries
- sometimes retrieving the values, but it's limited - see docs
Row-based original values storage: stored="true"
Stored fields are used to store the original (not analysed) value per document:
Stored values for Car 1:
name: "VW Golf hatchback"
price: 200
Stored values for Car 2:
name: "Toyota Corolla hatchback"
price: 100
Stored values for Car 3:
name: "Toyota Auris Touring"
price: 50
Use cases: when we want to get the values from the index
Tip
The common practice is NOT using search engine for retrieving values, due to performance reasons. Usually it's enough to return only docIds from the search engine, and use some external storage to hydrate the data.
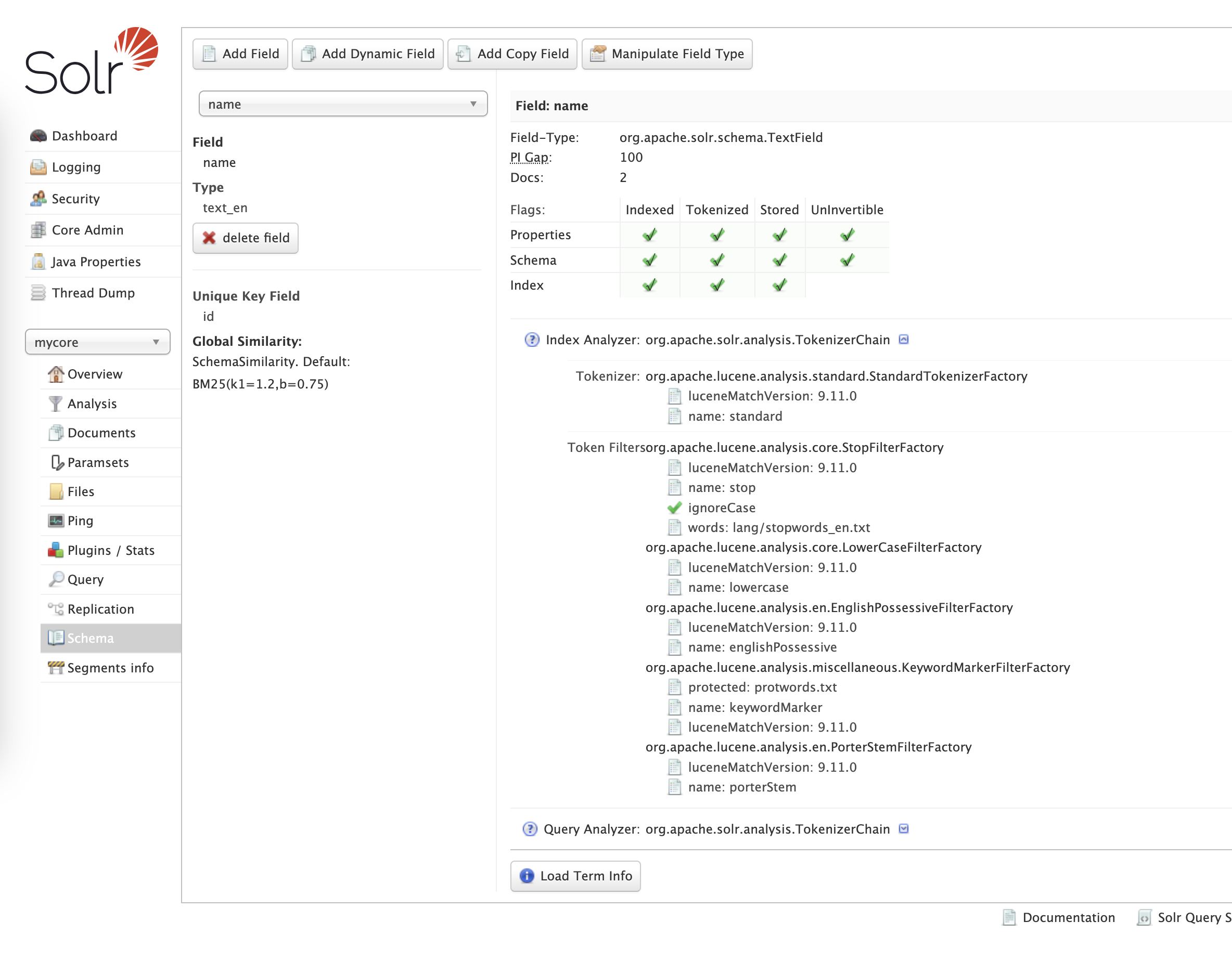
TextFields: analyzers and tokenizers
In case of solr.TextField, it's possible to define how the field is analyzed (modified) during indexing,
separately for the querying and indexing
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100" multiValued="true">
<analyzer type="index">
<tokenizer name="standard"/>
<filter name="stop" ignoreCase="true" words="stopwords.txt" />
<filter name="lowercase"/>
</analyzer>
<analyzer type="query">
<tokenizer name="standard"/>
<filter name="stop" ignoreCase="true" words="stopwords.txt" />
<filter name="synonymGraph" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter name="lowercase"/>
</analyzer>
</fieldType>
tokenizer - how to split text into tokens, some examples:
standard- splits by whitespace and punctuationwhitespace- splits by whitespacepattern,simplePattern- splits by regexpkeyword- does not split, treat the whole string as a single tokennGram- splits into substrings of a specific lengthpathHierarchy- used to tree-like paths (f.ex. directory structure)- and more...
filter - how to modify tokens, some examples:
asciiFolding- replaces national characters with latin equivalents (ą=>a)englishMinimalStem- changes plurals into singulars (English)lowercase- lowercasestop- filters our stopwordsshingle- creates groups of consecutive tokenssynonymGraph- allows to define synonyms- and much more...
Support in the SolrUI