Solr querying
Docs and sources:
- Query Syntax and Parsers
- Common Query Parameters
- Standard Query Parser
- DixMax Query Parser
- Extended DisMax (eDisMax) Query Parser
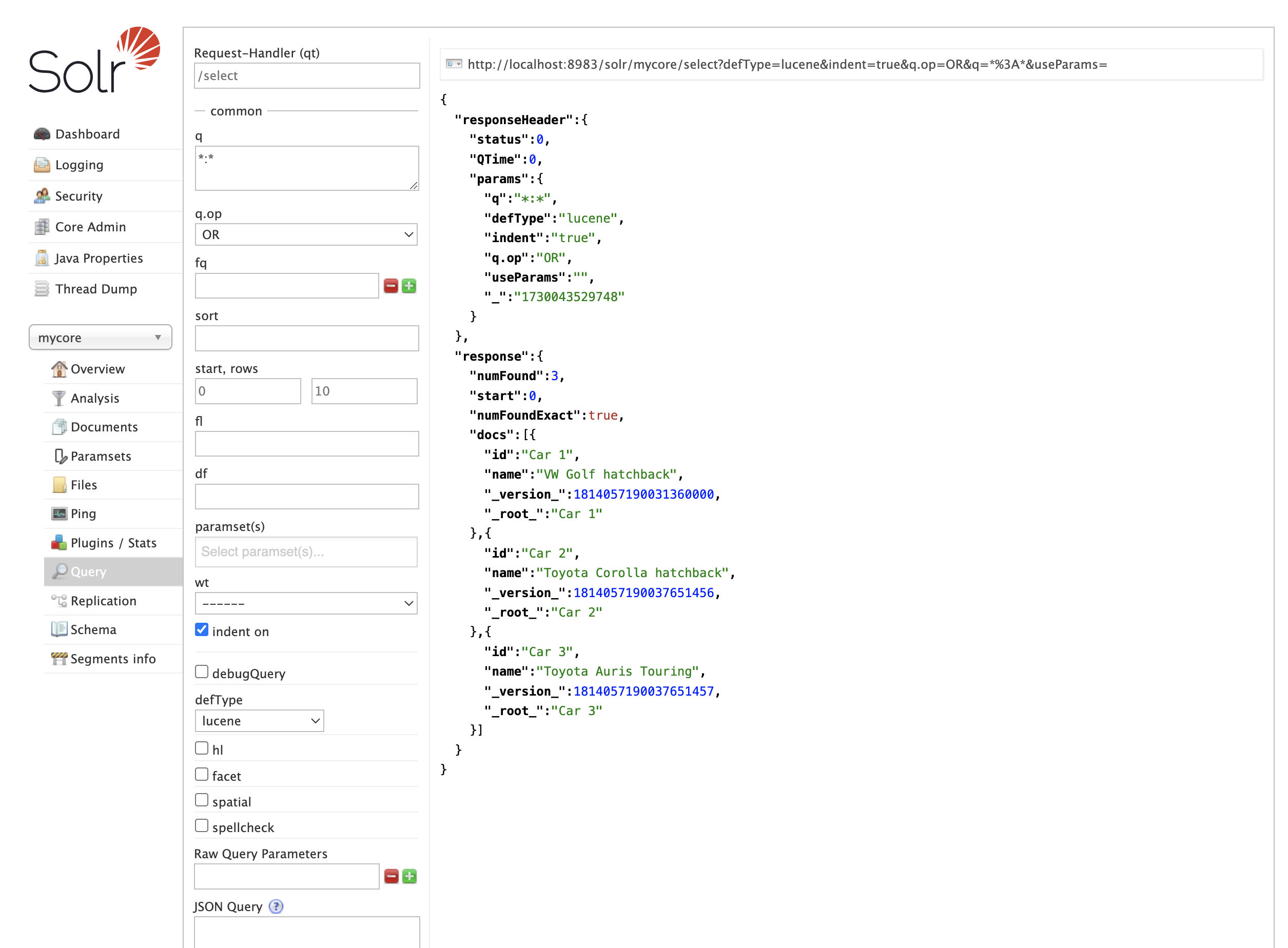
How do send queries to Solr?`
Basic example:
About QueryParsers
The query syntax is strictly dependent on the QueryParser being used. Each parser has different syntax and capabilities.
Common query parameters
Full list and description: Common Query Parameters
Some examples:
| param | description | examples | defaultValue |
|---|---|---|---|
defType |
which QueryParser should be used |
|
lucene |
q |
main query | depending on QueryParser | none |
fq |
filter query | fq=popularity:[10 TO *]&fq=section:0 |
none |
sort |
result set sorting order |
|
score desc |
start |
for pagination: offset of page start | 0 |
0 |
rows |
for pagination: number of documents | 72 |
10 |
fl |
fields to retrieve |
|
* |
debug |
return debug information |
|
none |
timeAllowed |
the amount of time, in milliseconds, allowed for a search to complete | 2000 | none |
wt |
output format |
|
json |
echoParams |
should the query parameters be included in the response |
|
none |
Additionally, you can specify:
Lucene Query Parser (default)
Example:
Docs: Standard Query Parser
| param | description | defaultValue |
|---|---|---|
q |
main query (mandatory); see examples below | none |
q.op |
AND or OR, relation between tokens |
OR |
df |
which (single) field should be searched, eg. name |
none |
The main query syntax by example:
vw golf- searches for these words in fields defined indf, and joins them usingq.op"vw golf"- quotes mark phrases. Tokens must be next to each other.gol?,gol*- wildcards are supportedgolf~2- tilde after word (not phrase) - fuzzy searching, finds similar words"vw golf"~3- tilde after phrase (not word) - proximity search, tokensvwandgolfmust be within 3 words of each othername:vw- possibility to define explicit fields -<field-name>:<query>name:"vw golf",name:gol?,name:gol*,name:golf~2- it's all supportedname:*- finds documents, which have some value in fieldnamesetprice:[52 TO 1000]- ranges for numeric fields (including those borders)price:{52 TO 1000}- ranges for numeric fields (EXCLUDING those borders)price:{52 TO 1000],price:[* TO 1000]- also possiblevw^4 golf- boosting; tokenvwis boosted (more important) four timesvw OR golf,vw AND golf,vw || golf,vw && golf- explicitly specify operator between tokens"vw golf" OR toyota- also possible(vw AND golf) OR toyota- also possiblevw NOT golf,vw ! golf- excluding tokens+vw -golf- must includevw, cannot includegolf
DisMax
Example:
The main goal of DisMax was to separate the user's query from how the query should be processed. DisMax doesn't support Lucene Query Parser's syntax!
Docs: DixMax Query Parser
| param | description | defaultValue |
|---|---|---|
q |
main query (mandatory): only basic syntax is supported:
|
none |
q.alt |
query which should be used if main query is empty | none |
qf |
which fields should be searched with their weights, eg. brand^2.5 model^0.5 |
none |
mm |
minimum should match; number of SHOULD MATCH words that must match the document; might be absolute or percentage | none |
pf |
phrase fields; if the tokens appear in close proximity in this field, the document is boosted, eg title^4 description^1 |
none |
ps |
phrase slop; the maximum distance between tokens to form a phrase | none |
tie |
tie breaker: see the docs | none |
bq |
boost query: see the docs | none |
bf |
boost function: see the docs | none |
The main query syntax by example:
q=vw golf&qf=brand^2 model- search for wordsvw(optional) andgolf(optional) in fieldsbrand(higher priority) andname(lower priority)q=+vw golf&qf=brand^2 model- search for wordsvw(mandatory) andgolf(optional) in fieldsbrand(higher priority) andname(lower priority)q=+"vw golf"&qf=brand^2 model- search for phrase"vw golf"(mandatory) in fieldsbrand(higher priority) andname(lower priority)q=+vw +golf&qf=brand^2 model- search for wordsvw(mandatory) andgolf(mandatory) in fieldsbrand(higher priority) andname(lower priority)q=+vw +golf -toyota&qf=brand^2 model- search for wordsvw(mandatory) andgolf(mandatory) in fieldsbrand( higher priority) andname(lower priority); documents cannot containtoyotaq=vw golf hatchback&qf=brand^2 model&mm=2- search for wordsvw(optional) andgolf(optional) andhatchback(optional) in fieldsbrand(higher priority) andname(lower priority); the document is returned if at least two of these optional words have been foundq=vw golf hatchback&qf=brand^2 model&mm=50%- search for wordsvw(optional) andgolf(optional) andhatchback(optional) in fieldsbrand(higher priority) andname(lower priority); the document is returned if at least half of the optional words have been foundq=vw golf&qf=brand^2 model&pf=name^5- search for wordsvw(optional) andgolf(optional) in fieldsbrand( higher priority) andname(lower priority); if the phrase "vw golf" if found in fieldname, boost the documentq=vw golf&qf=brand^2 model&pf=name^5&ps=4- search for wordsvw(optional) andgolf(optional) in fieldsbrand(higher priority) andname(lower priority); if the phrase "vw golf" if found in fieldname, boost the document; maximum allowed distance between these words is 4
eDisMax
Example:
Extended DisMax, combination DisMax and Lucene Query Parser with add-ons.
As a first approximation, you can think of eDixMax as DisMax, where:
- you can use
ANDandORinsideqparameter - you can specify a
boostfunction in a better way than in DisMax - have some additional enhancements
For better understanding, refer to the docs: Extended DisMax (eDisMax) Query Parser